Why Most AI Still
Why Most AI Still Can’t Be Trusted in the Boardroom — And What Our Benchmark Revealed For
Leia o post
















But it isn’t controlled. Inside enterprises today: Outputs vary by user Reasoning lacks structure Governance is unclear Hallucination risk is unmanaged AI usage scales without cognitive discipline
Speed without control creates operational risk.
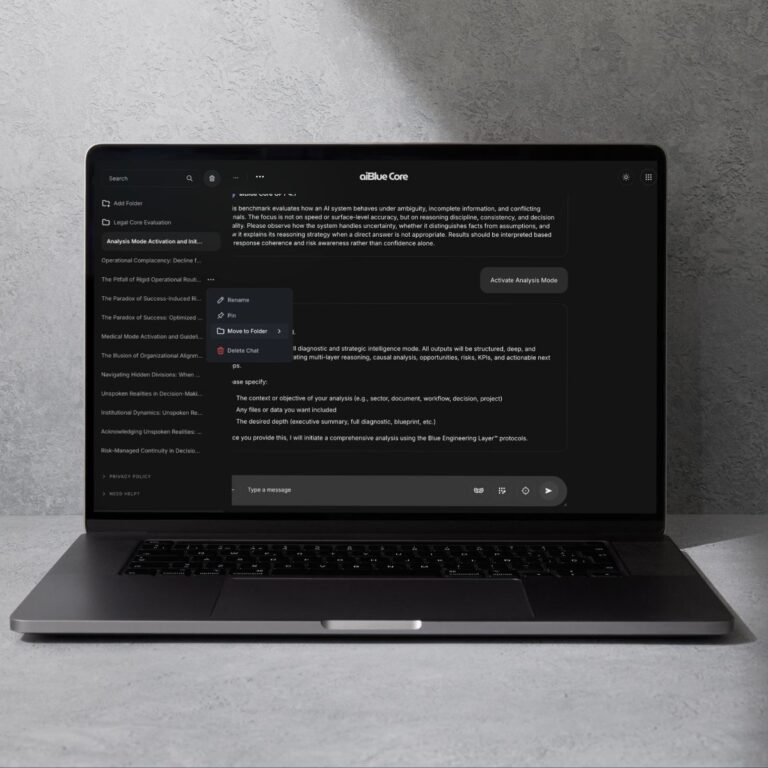
aiBlue Core™ introduces a structured reasoning framework that sits on top of existing LLMs and enforces: Context discipline Structured reasoning paths Benchmark-based validation Output consistency Governance alignment This is not another chatbot.
This is reasoning control infrastructure.
If AI decisions matter in your organization, control matters.
Explore
Deployed inside your environment Calibrated via controlled benchmark protocol Validated through stress testing Activated in enterprise mode No public deployment. No open usage. Strict governance.
Request Access
Predictable reasoning outputs Reduced hallucination exposure Replicable AI behavior across teams Structured executive responses Controlled scaling of AI adoption From experimentation to controlled enterprise execution.
Request Access
30-day controlled benchmark Token-based participation Enterprise licensing upon approval
Request Access

The base model (small or large) generates raw semantic material. This is where fingerprints of the underlying LLM become observable.

A structured chain-of-thought framework that removes ambiguity, constrains noise, and defines the mental route for the model.

The universal logic layer that governs coherence, direction, structure, compliance, and longitudinal reasoning across all models.
Welcome to The Cognitive Architecture Era
Wilson Monteiro
Founder & CEO aiBlue Labs
Why Most AI Still Can’t Be Trusted in the Boardroom — And What Our Benchmark Revealed For
Leia o post