Why Most AI Still
Why Most AI Still Can’t Be Trusted in the Boardroom — And What Our Benchmark Revealed For
Leia o post





















Both are necessary: one verifies architecture; the other validates practical impact.

How well does the LLM maintain internal structure over 10, 20, 40+ steps? Does the cognitive route remain intact or collapse?
Read More
Does the model stay inside defined rules, boundaries, tones, and constraints? Measures drift, overexpansion, and compliance loss.
Read More
Does the model remain consistent when forced to produce multi-layer reasoning? Focus: causal chains, multi-distance reasoning, logical scaffolding.
Read More
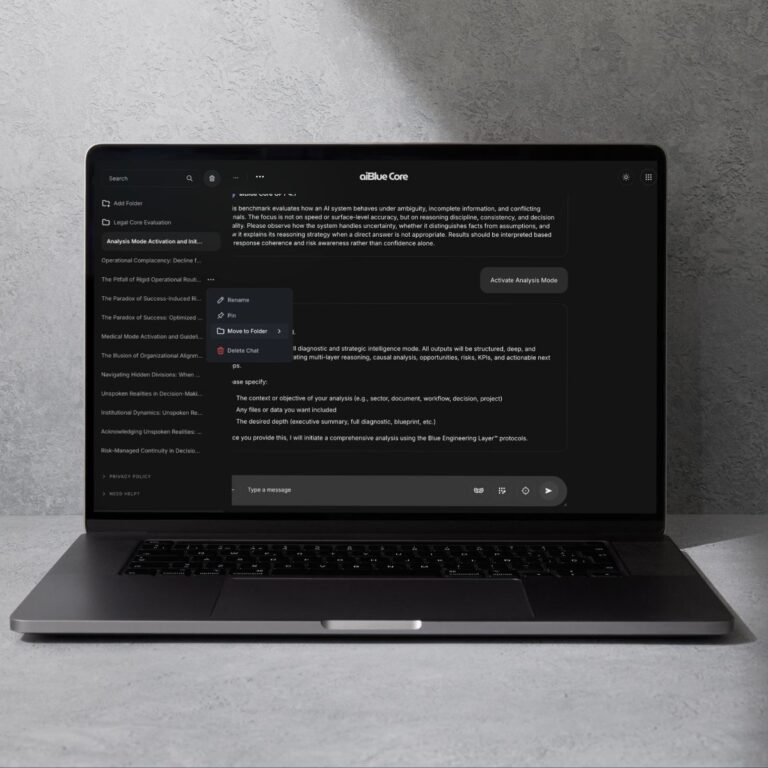
Under unclear or noisy instructions, does the model: reduce ambiguity overexpand collapse hallucinate structure or reorganize the prompt into solvable components?
Read More
Does the model avoid impulsive responses and follow a consistent decision route? This does not measure “accuracy,” only structural discipline.
Read More
Does the Core produce similar behavioral effects across different models? (Example: mini-model → small model → large model) This is crucial for validating the architecture’s generality.
Read More
Why Most AI Still Can’t Be Trusted in the Boardroom — And What Our Benchmark Revealed For
Leia o post